
谷歌近日为其Gemini 2.5 AI模型推出了一项新功能,用户可以通过自然语言指令直接分析并突出显示图像内容。
这项"对话式图像分割"技术超越了传统的图像识别方式——传统方法通常只能通过固定类别(如"狗"、"汽车"或"椅子")来识别物体。现在,Gemini能够理解更复杂的语言描述,并将其应用于图像的特定部分。该模型可以处理关系型查询(如"打伞的人")、逻辑指令(如"所有没有坐着的人"),甚至是没有明确视觉轮廓的抽象概念(如"杂物"或"损坏")。得益于内置的文本识别功能,Gemini还能识别需要读取屏幕上文字的图像元素,例如展示柜中的"开心果果仁蜜饼"。该功能支持多语言指令,并能根据需要提供其他语言的物体标签,比如法语。
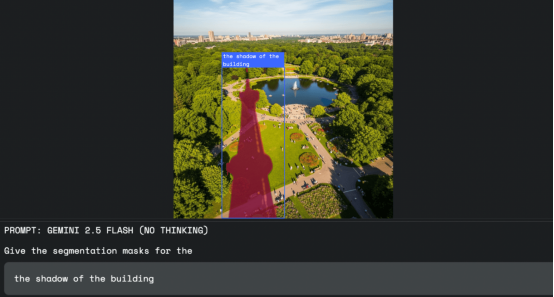
图片来源:谷歌
实际应用场景
据谷歌介绍,这项技术可应用于多个领域。例如在图像编辑中,设计师不再需要使用鼠标或选择工具,只需说出他们想要选择的内容,比如"选择建筑物的阴影"。
在工作场所安全方面,Gemini可以扫描照片或视频中的违规行为,例如"所有在建筑工地未戴安全帽的人员"。
该功能在保险行业也很有用:理赔员可以发出"突出显示所有遭受风暴损坏的房屋"等指令,自动标记航拍图像中受损的建筑物,与手动检查每处房产相比节省了大量时间。
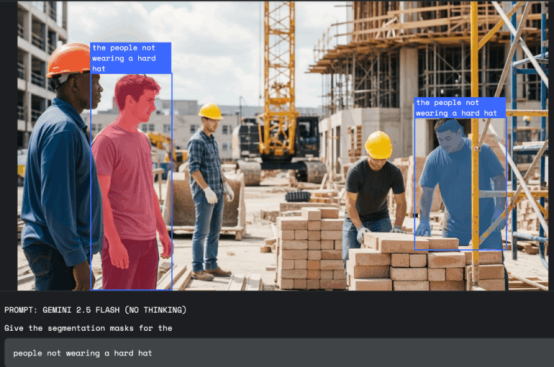
图片来源:谷歌
无需特殊模型
开发者可以通过Gemini API访问该功能。所有请求都由具备此功能的Gemini模型直接处理。
返回的结果采用JSON格式,包括所选图像区域的坐标(box_2d)、像素掩码(mask)和描述性标签(label)。
为了获得最佳效果,谷歌建议使用gemini-2.5-flash模型,并将"thinkingBudget"参数设置为零以触发即时响应。
用户可通过Google AI Studio或Python Colab进行初步测试。
精选文章: