这款升级版AI视频生成器新增了音效和精准编辑工具,表明谷歌正加紧挑战OpenAI的Sora 2。

谷歌今日发布了其AI视频生成器Veo的更新版本——Veo 3.1。此版本为所有功能添加了音频支持,并引入了新的编辑功能,旨在让创作者对其视频片段拥有更多控制权。
此次发布之际,正值OpenAI的竞争产品Sora 2应用在应用商店榜单上攀升,并引发了关于AI生成内容充斥社交媒体的讨论。
这一时机选择表明,谷歌希望将Veo 3.1定位为Sora 2那种病毒式社交传播方式的专业替代品。OpenAI于9月30日推出了Sora 2,其界面采用TikTok风格,优先考虑分享和混剪功能。
该应用在五天内下载量达到100万次,并登顶苹果App Store排行榜。Meta也采取了类似策略,推出了其由AI视频驱动的虚拟社交媒体平台。
用户现在可以使用"多图成视频"工具,创建带有同步环境噪音、对话和拟音效果的视频。该工具可将多张参考图像组合成单个场景。
"帧间动画"功能可生成起始图像和结束图像之间的过渡效果,而"延长"功能则通过延续现有视频最后一秒的运动,生成最长可达一分钟的视频片段。
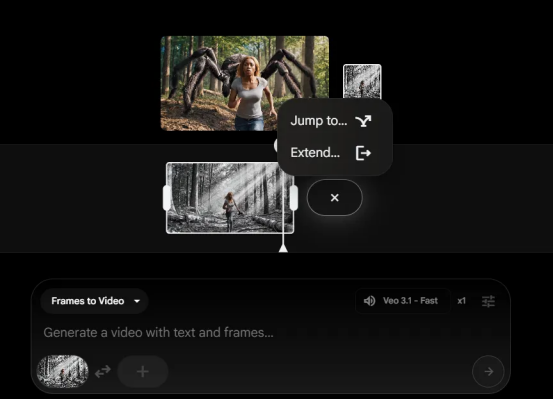
新的编辑工具允许用户在生成的场景中添加或移除元素,并自动调整阴影和光照。该模型可生成1080p分辨率、横屏或竖屏比例的视频。
该模型通过Flow向普通用户开放,通过Gemini API向开发者开放,并通过Vertex AI向企业客户开放。使用"延长"功能可以创建最长一分钟的视频,该功能能够延续现有片段最后一秒的运动。
2025年,AI视频生成市场变得异常拥挤:Runway的Gen-4模型面向电影制作人,Luma Labs为社交媒体提供快速生成服务,Adobe将Firefly Video集成到Creative Cloud中,而xAI、Kling、Meta和谷歌的更新则专注于提升真实感、音效生成和提示词遵循能力。
但它到底有多好呢?我们对其进行了测试,以下是我们的一些印象。
模型测试
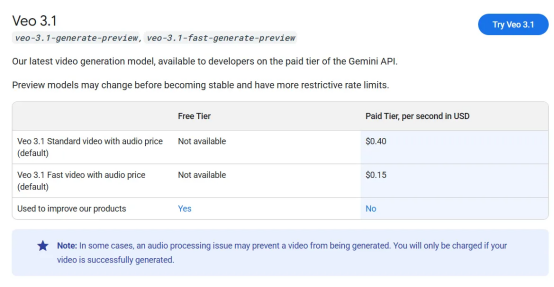
如果你想尝试它,最好准备充足的预算。Veo 3.1是目前最昂贵的视频生成模型,与Sora 2价格相当,仅低于每次生成费用是其二倍多的Sora 2 Pro。
免费用户每月收到100点信用额度来测试系统,这大约足够每月生成五个视频。通过Gemini API,带音频的Veo 3.1视频生成成本约为每秒0.40美元,而一个名为Veo 3.1 Fast的更快变体成本为每秒0.15美元。
对于愿意以此价格使用的用户,以下是它的优缺点。
Veo 3.1相比其前身确实有所改进。该模型能很好地处理连贯性,并表现出对上下文环境更好的理解能力。
它适用于不同的风格,从照片写实主义到风格化内容。
我们要求模型融合一个场景,该场景从绘图开始,逐渐过渡到实景镜头。它处理这项任务的表现优于我们测试过的任何其他模型。
在没有任何参考帧的情况下,Veo 3.1在文生视频模式下产生的结果,比使用相同提示词但附带初始图像时产生的结果更好,这令人惊讶。
其代价是运动速度。Veo 3.1优先考虑连贯性而非流畅度,这使得生成快节奏动作具有挑战性。
元素移动较慢,但在整个片段中保持一致性。在快速运动方面,Kling仍然领先,尽管它需要更多尝试才能获得可用的结果。
Veo凭借图生视频功能建立了声誉,而其效果总体上仍令人满意——但存在注意事项。这似乎是本次更新的一个较弱环节。当使用不同宽高比的图像作为起始帧时,模型难以维持它曾经拥有的连贯性水平。
如果提示词与输入图像逻辑上应有的后续内容偏离太远,Veo 3.1会设法"作弊"。它会生成不连贯的场景,或者在位置、布景或完全不同的元素之间跳跃的片段。
这既浪费时间又浪费信用点,因为这些片段因格式不匹配而无法编辑成更长的序列。
当它成功工作时,效果看起来非常棒。但达到理想效果部分靠技巧,部分靠运气——而且主要是靠运气。
元素成视频
此功能类似于视频修复,允许用户在场景中插入或删除元素。但不要期望它能保持完美的连贯性或完全使用你提供的精确参考图像。
例如,下面的视频是使用以下三张参考图和提示词生成的:"一男一女在未来城市中奔跑时偶然相遇,那里有一个比特币标志的全息图在旋转。男子对女子说:'快,比特币暴跌了!我们必须买入更多!!'"

无论是城市还是角色都并非严格按照参考图呈现。
然而,角色穿着参考图中的衣服,城市也与图片中的城市相似,事物呈现的是元素的"概念",而非元素本身。
Veo 3.1将上传的元素视为灵感来源,而非严格的模板。它会生成遵循提示词并包含与你提供的对象相似之物的场景,但别浪费时间试图把自己插入到电影中——那是行不通的。
一个变通方法是:先使用Nanobanana或Seedream上传元素并生成一个连贯的起始帧,然后将该图像喂给Veo 3.1,这样它生成的视频中,角色和物体在整个场景中的形变会最小。
带对话的文生视频
这是谷歌的卖点。Veo 3.1在唇形同步方面的处理能力优于当前任何其他可用模型。在文生视频模式下,它能生成与场景元素匹配的连贯环境音。
其对话、语调、声音和情感都非常准确,击败了竞争对手。
其他生成器可以产生环境噪音,但只有Sora、Veo和Grok能生成实际的词语。
在这三者中,Veo 3.1在文生视频模式下获得良好结果所需的尝试次数最少。
带对话的图生视频
这正是问题所在之处。带对话的图生视频存在与标准图生视频相同的问题。Veo 3.1过于优先考虑连贯性,以至于忽略了对提示词的遵循和参考图像。
例如,这个场景是使用"元素成视频"部分展示的参考图生成的。
如你所见,我们的测试生成了一个与参考图像完全不同的主体。视频质量非常出色——语调和手势都很到位——但那不是我们上传的人,使得结果毫无用处。
对于这个用例,Sora的混音功能是最佳选择。该模型可能受到内容审查,但其图生视频能力、逼真的唇形同步以及对语调、口音、情感和真实感的关注,使其成为明显的赢家。
Grok的视频生成器位居第二。它比Veo 3.1更好地尊重了参考图像,并产生了更优的结果。这里是使用相同参考图像和提示词的一次生成样例。
如果你不想折腾Sora的社交应用,或者无法使用它,Grok可能是你的最佳选择。它同样未经审查但受监管,所以如果你需要那种特定的方式,马斯克已经为你考虑到了。
精选文章: