
Google Deepmind 正在为 Gemini 应用添加一款全新的图像编辑模型,该模型能按需对照片进行大幅修改,同时确保人物和动物保持可识别性。
这款全新的 “Gemini 2.5 Flash 图像生成” 模型基于 Gemini 早期原生图像生成工具构建,但在提示词处理上更加精准。谷歌表示,其表现通常优于 ChatGPT 所使用的 GPT-4o 模型,尤其是在遵循文本指令进行图像编辑方面。虽然许多纯图像模型仍在与提示词准确性作斗争,但 Gemini 2.5 Flash 的准确率更高。
一个关键特性是“角色一致性”:该模型能够使人物、动物或物体在多张图像中保持视觉上的一致,即使姿势、背景或光线发生变化。

Gemini 2.5 Flash 能在新场景中保持角色一致性。其表现是否优于更复杂的微调方法仍有待观察。| 图片来源:Google Deepmind
这为创建图像系列或多角度产品拍摄开辟了新的可能性。谷歌表示,该模型非常适合生成一致的品牌资产和产品目录,并声称 Gemini 2.5 Flash 在广泛的编辑任务上优于其他图像系统。
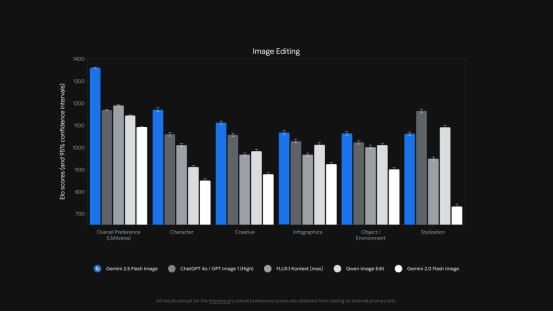
Gemini 2.5 Flash 在多项人工评分的图像编辑基准测试(ELO 分数)中优于之前的模型。| 图片来源:Google
该模型还支持通过文本提示进行精确的局部编辑。用户可以模糊背景、去除瑕疵、添加颜色或擦除整个对象,而无需手动选择。一款名为 “PixShop”的模板应用 通过简单的界面和提示控制展示了这些编辑功能。
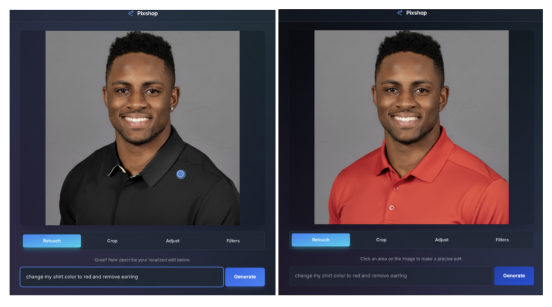
PixShop 展示了 Gemini 2.5 Flash 基于文本的编辑工具。| 图片来源:Google Deepmind
图像合成、风格迁移与真实世界推理
Gemini 2.5 Flash 可以一次性融合最多三张图像。例如,您可以将产品照片和房间照片结合起来,创造出逼真的室内场景。包含多个元素的复杂构图可以通过单次提示生成。谷歌还提供了一个 交互式画布工具 用于多图像融合。

Gemini 2.5 Flash 将多张图像混合成一个构图。| 图片来源:Google Deepmind
该模型也能处理风格迁移,将图案、颜色或纹理从一个物体转移到另一个物体,同时保持形状和细节不变。典型的例子包括带有蝴蝶图案的连衣裙或带有花卉纹理的靴子。

Gemini 2.5 Flash 跨物体应用图案和风格。| 图片来源:Google Deepmind
Gemini 2.5 Flash 还能可视化简单的因果关系,谷歌称之为“真实世界推理”。在一个演示中,模型生成了一张气球飘向仙人掌的图像,然后又生成了另一张显示接下来会发生什么的图像。

该模型可以阐释因果关系,例如气球遇到仙人掌。| 图片来源:Google Deepmind
谷歌表示,这些语义特性借鉴了 Gemini 2.5 的世界知识。您可以使用一款 遵循文本指令的绘画应用 亲自尝试这些功能。
面向用户和开发者开放
Gemini 2.5 Flash 图像工具现已可在 Gemini 应用 中使用。您无需在聊天栏中选择 “Imagen” 图像模型,而是需要在左上角切换到 “Flash” 语言模型才能使用新功能。这个设置起初可能有点令人困惑,但考虑到 Gemini 基于语言的编辑方法,这是合理的。
要使用 Gemini 2.5 Flash 图像编辑,请在 Gemini 应用中选择 “Flash” 语言模型。| 图片来源:THE DECODER 截图
选择正确的模型后,您可以上传图像并向 Gemini 发出编辑指令。每张图像都带有可见水印和不可见的 SynthID 数字水印。
Gemini 2.5 Flash Image 也通过 Gemini API、Google AI Studio 和 Vertex AI 提供预览版。定价为每百万输出 tokens 30 美元。每张图像使用约 1290 个 tokens,即每张图像约 0.039 美元,与 Gemini 2.0 Flash Image 相同。
精选文章: