
北京智源研究院的研究团队近日发布了OmniGen 2,这款开源系统能够实现文生图、图像编辑和上下文图像生成。
相较于2024年11月发布的第一代,OmniGen 2采用双路解码架构:文本与图像路径拥有独立参数,并配备解耦的图像标记器。研究团队表示,这种设计能在保留核心文本生成能力的同时,基于现有多模态大语言模型进行扩展。

OmniGen 2支持多种提示词和艺术风格,但其写实图像仍存在轻微模糊问题 | 图片来源:吴等人
该模型以Qwen2.5-VL-3B Transformer为多模态基座,图像生成模块采用约40亿参数的定制扩散Transformer。当遇到特殊标记"<|img|>"时,系统会自动从文本生成切换至图像生成模式。
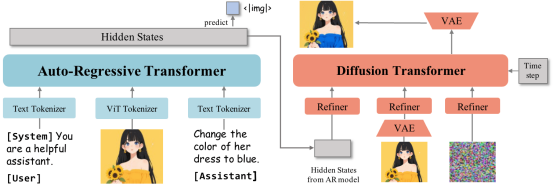
双路解码架构:自回归Transformer处理文本,扩散Transformer生成图像,兼顾语言能力与视觉质量 | 图片来源:吴等人
训练数据包含1.4亿张开源与专有图像。团队还创新性地利用视频素材——例如提取同一人脸微笑前后的帧序列,通过语言模型自动生成对应的编辑指令。

支持局部编辑而无需全图重生成 | 图片来源:吴等人
在上下文图像生成方面,OmniGen 2能追踪视频中的人物或物体跨帧表现,从而学习同一主体在不同场景下的特征。

多图融合生成能力 | 图片来源:吴等人
创新性多模态位置编码
团队提出的"Omni-RoPE"位置嵌入技术,将位置信息分解为序列ID、模态ID和图像元素2D坐标三重标识。这种设计使模型能精准处理多输入源的时空组合。
独特之处在于,OmniGen 2仅将VAE(变分自编码器)特征作为扩散解码器输入,而非整合到主语言模型中。这一选择简化了架构,更好保留了语言理解能力。
自反思迭代优化机制
核心亮点是自反思机制:模型可评估生成图像的质量,通过多轮迭代进行改进。系统能识别缺陷并给出具体修正方案。
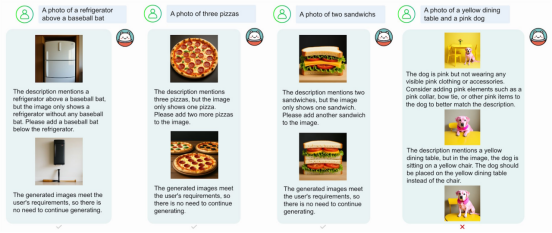
自反思机制实现图像自动优化 | 图片来源:吴等人
由于缺乏上下文图像生成的权威基准,团队推出了OmniContext评测体系,包含角色、物体、场景三大类,每类8个子任务各50个样本。
GPT-4.1负责评估生成结果,从提示准确性和主体一致性两个维度进行0-10分打分。OmniGen 2以7.18分超越所有开源模型,而近期新增原生图像生成的GPT-4o得分为8.8分。
在文生图任务中,OmniGen 2于GenEval和DPG-Bench等基准测试表现优异;图像编辑任务上更是创下开源模型的新纪录。
当前局限包括:英文提示效果优于中文,体型修改不够精准,输出质量依赖输入图像。对于模糊的多图提示,需明确指定物体位置指令。
精选文章: