
近期,基于文本的图像生成模型已能根据自然语言描述自动创建高分辨率、高质量的图像。然而,当输入"创意"这类抽象文本时,即便是Stable Diffusion这样的典型模型,其生成真正具有创造力图像的能力仍显不足。
韩国科学技术院(KAIST)的研究人员开发了一项新技术,无需额外训练即可提升Stable Diffusion等文本生成图像模型的创造力,使AI能够设计出突破常规的创意椅子造型。
KAIST金在哲人工智能研究生院的崔宰硕教授团队与NAVER AI实验室合作,开发了这项无需额外训练即可增强AI生成模型创造力的技术。该研究已发布于arXiv预印本服务器论文链接,代码开源在GitHub。
崔教授团队通过放大文本生成图像模型内部特征图的技术来增强创意生成能力,同时发现模型浅层模块对创意生成起关键作用。他们证实:将特征图转换至频域后,若放大高频区域数值会导致噪点或色彩碎片化。
因此,研究团队证明放大浅层模块的低频区域能有效提升创意生成效果。
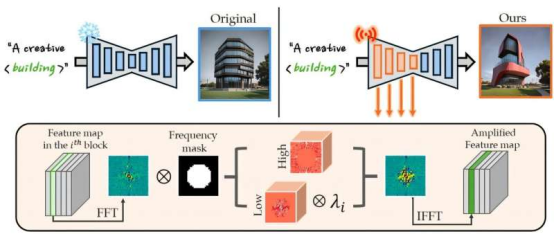
研究团队将原创性和实用性定义为创造力的两大核心要素,提出了一种能自动选择生成模型各模块最佳放大值的算法。通过该算法,适当放大预训练Stable Diffusion模型的内部特征图,无需额外分类数据或训练即可增强创意生成能力。
研究团队通过多维度指标定量证明,其算法生成的图像比现有模型更具新颖性,同时未显著牺牲实用性。特别是在SDXL-Turbo模型(为提升Stable Diffusion XL生成速度开发的版本)中,该技术有效缓解了模式崩溃问题,显著提升了图像多样性。用户研究表明,相比现有方法,人类评估者也认为其新颖性与实用性的平衡度有显著改善。

论文共同第一作者、KAIST博士生韩知妍和权多熙表示:"这是首个无需重新训练或微调即可增强生成模型创意能力的方法。我们证明通过特征图操控,能激发已训练AI生成模型中潜在的创造力。"
她们补充道:"这项研究使得仅用文本就能从现有训练模型中轻松生成创意图像。预计将为创意产品设计等领域带来新灵感,推动AI模型在创意生态中的实用化应用。"
该研究由KAIST金在哲人工智能研究生院的博士生韩知妍和权多熙共同完成,已于6月16日在计算机视觉与模式识别国际会议(CVPR)上发表。
精选文章: