
加州大学默塞德分校与Adobe的最新合作,在人体图像补全领域取得突破性进展。这项名为CompleteMe的技术不仅能修复受损图像,还能根据参考图像为人物"换装",在虚拟试衣、动画制作和照片编辑等场景展现强大潜力。

CompleteMe系统通过参考图像(中列)为原始图像(左列)生成自然逼真的补全效果(右列)。案例来自论文补充材料:查看详情
这项发表于arXiv的研究采用双U-Net架构与区域聚焦注意力模块(RFA),通过参考图像指导系统修复被遮挡的人体部位:

CompleteMe能精准适配参考图像内容至目标区域
技术核心:双网络协同作战
系统由两大核心构成:
参考U-Net:处理多角度参考图像,提取细节特征
补全U-Net:整合掩码图像与参考特征,生成最终结果
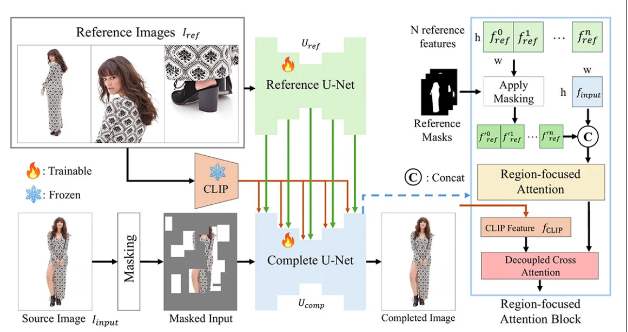
系统架构示意图 来源
关键技术突破包括:
1区域聚焦注意力机制:通过空间掩码确保模型仅关注相关区域
2CLIP语义特征融合:结合全局语义理解与局部细节特征
3复合掩码策略:随机网格遮挡+人体形状掩码组合训练
性能碾压现有方案
在包含417组测试数据的定制化基准上,CompleteMe在多数指标上全面领先:
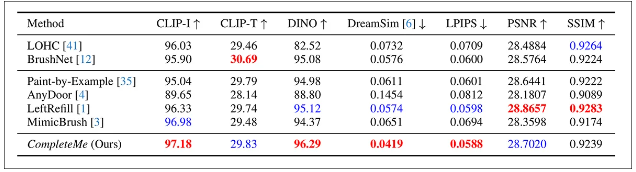
定量评估结果(数值越高越好)
用户研究显示,在2895组对比测试中,CompleteMe生成的图像在视觉质量和特征保真度上获得显著偏好:

用户调研结果
典型案例对比可见,传统方法(红框标注)难以还原纹身、特殊服饰等细节:

与参考基线方法对比,CompleteMe精准保留参考图像特征
应用前景与局限
虽然项目GitHub页面暂未开源代码,但其在时尚领域的应用潜力已引发关注。研究人员特别指出,该系统在复杂姿势、精细服饰等挑战性场景表现优异。

这项研究标志着AI图像编辑从"无中生有"迈向"按需定制"的新阶段,为数字内容创作提供了更精准的工具。建议读者深入研读完整论文与补充材料,以全面了解技术细节。
精选文章: