
对于普通用户而言,若想将个人形象嵌入主流AI图像视频生成工具,往往面临一个现实门槛:除非你是家喻户晓的公众人物,否则必须预先通过个人照片集训练专属的LoRA(低秩适应)模型。这套"数字身份证"一旦建立,生成系统便能在后续创作中精准还原用户特征。
这项被称为"AI定制化"的技术,其发展历程颇具戏剧性。2022年Stable Diffusion横空出世后不久,谷歌研究院便率先推出名为DreamBooth的闭源解决方案。这个需要数GB存储空间的定制模型,很快被技术极客破解改良,最终以开源形式回馈社区。
而LoRA模型的问世彻底改变了游戏规则。相较于前代方案,它具有三大突破性优势:训练流程大幅简化、模型体积显著缩小、生成质量却分毫不减。这些特性使其迅速占领市场,不仅成为Stable Diffusion系列模型的标配,更在后续问世的Flux等图像模型,以及混元视频、万2.1等视频生成平台上大放异彩。
技术迭代之痛与破局之道
我们注意到一个持续存在的行业痛点:每当底层模型更新迭代,用户就必须重新训练配套LoRA。这对内容创作者而言无异于噩梦——耗费大量资源建立的定制模型,很可能因技术升级而一夜之间沦为"数字废铁"。
这一困境催生了学界对"零样本定制"技术的研究热潮。该技术的革命性在于:用户仅需提供少量样本图片,系统即可实时解析特征并融入生成过程,彻底跳过了传统方案中繁琐的数据准备和模型训练环节。如图所示,采用PuLID框架的系统不仅能实现无缝换脸,更能将人物特征与艺术风格完美融合。

要用通用的适配器(adapter)来取代像LoRA这样既费时费力又脆弱的系统,这个想法确实很棒(也很受欢迎),但挑战也不小。LoRA训练过程中那种对细节的极致把控和全面覆盖,想在IP-Adapter这类"一次性"模型上复现可不容易——毕竟这类模型必须在没有事先分析大量身份图像的优势下,达到和LoRA同等的细节处理能力和灵活性。
HyperLoRA
在此刻,字节跳动新发的一篇论文很有意思——他们提出了一种能实时生成LoRA代码的系统,这目前在零样本解决方案中可是独一份。

论文指出:
"基于适配器(Adapter)的技术(如IP-Adapter)会冻结基础模型的参数,采用插件式架构来实现零样本推理,但在人像合成任务中,这类方法往往缺乏自然度和真实感——这个问题不容忽视。"
"我们(字节跳动)提出了一种参数高效的自适应生成方法HyperLoRA,通过自适应插件网络动态生成LoRA权重,将LoRA的卓越性能与适配器方案的零样本能力相结合。"
"经过精心设计的网络结构和训练策略,我们实现了支持单图/多图输入的零样本个性化人像生成,在照片级真实感、还原度和可编辑性方面都表现出色。"
最实用的是,训练好的系统可直接兼容现有ControlNet,从而实现高度精细化的生成控制。

至于这个新系统最终是否会向终端用户开放,字节跳动历史来说可能很高——他们此前就开源了效果强大的口型同步框架LatentSync,最近又刚刚发布了InfiniteYou框架。
不太乐观的是,论文中完全没有提及开源意向,而且复现这项研究所需的训练资源极其庞大,即便是技术发烧友社区想要复现(就像当初对DreamBooth那样)也将面临巨大挑战。
这篇题为《HyperLoRA:人像合成的参数高效自适应生成》的新论文,由字节跳动及其旗下智能创作部门的七位研究者完成。
技术方案
这种新方法以Stable Diffusion的潜在扩散模型(LDM)SDXL为基础模型,不过其原理似乎适用于各类扩散模型(但考虑到训练要求——详见下文——可能难以应用于视频生成模型)。
HyperLoRA的训练过程分为三个阶段,每个阶段都旨在分离并保留学习权重中的特定信息。这种分阶段训练的设计目标,是在确保快速稳定收敛的同时,防止身份特征被服装、背景等无关元素干扰。
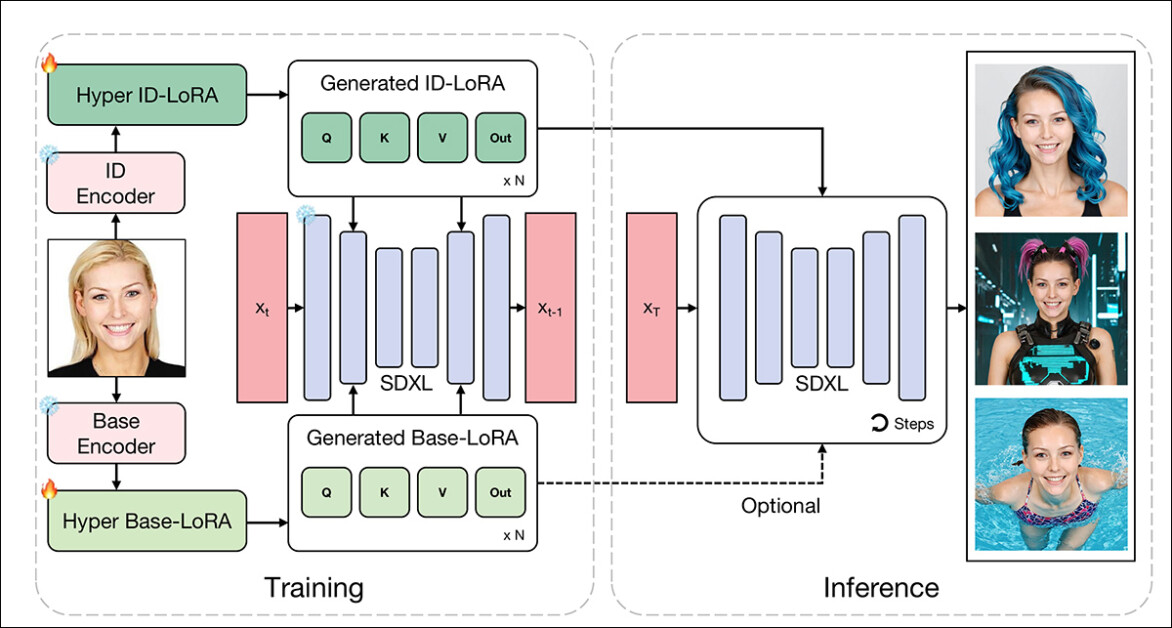
第一阶段完全专注于学习"基础LoRA"(示意图左下方模块),该模块专门捕捉与身份无关的细节。
为确保这种分离效果,研究人员刻意对训练图像中的人脸进行模糊处理,迫使模型只能学习背景、光线和姿势等特征——而非身份信息。这个"预热阶段"相当于过滤器,在进入身份特征学习前先排除低级干扰。
第二阶段则引入"身份LoRA"(示意图左上方模块),通过双通道架构编码面部特征:
CLIP视觉变换器(CLIP ViT)提取结构特征
InsightFace AntelopeV2编码器生成抽象身份表征
转型方法
CLIP特征能加速模型收敛,但存在过拟合风险;而Antelope表征更稳定但训练较慢。因此系统初期主要依赖CLIP特征,随后逐步引入Antelope,以此保持训练稳定性。
最终阶段会完全冻结CLIP引导的注意力层,仅保留与AntelopeV2连接的注意力模块继续训练。这种设计既能让模型持续优化身份特征保存能力,又不会破坏已学习组件的精确度和泛化性。
这种分阶段架构本质上是特征解耦的尝试——先将身份与非身份特征分离,再各自独立优化。它系统性地解决了个性化建模的常见问题:身份特征漂移、编辑灵活性不足,以及对非关键特征的过拟合。
动态权重生成机制
当CLIP ViT和AntelopeV2从人像中分别提取出结构特征和身份特征后,这些特征会被送入感知重采样器(源自IP-Adapter项目)——这是一个基于Transformer的模块,能将特征映射为一组紧凑系数。
系统采用两个独立的重采样器:
基础LoRA权重采样器:编码背景等非身份特征
身份LoRA权重采样器:专注面部身份特征
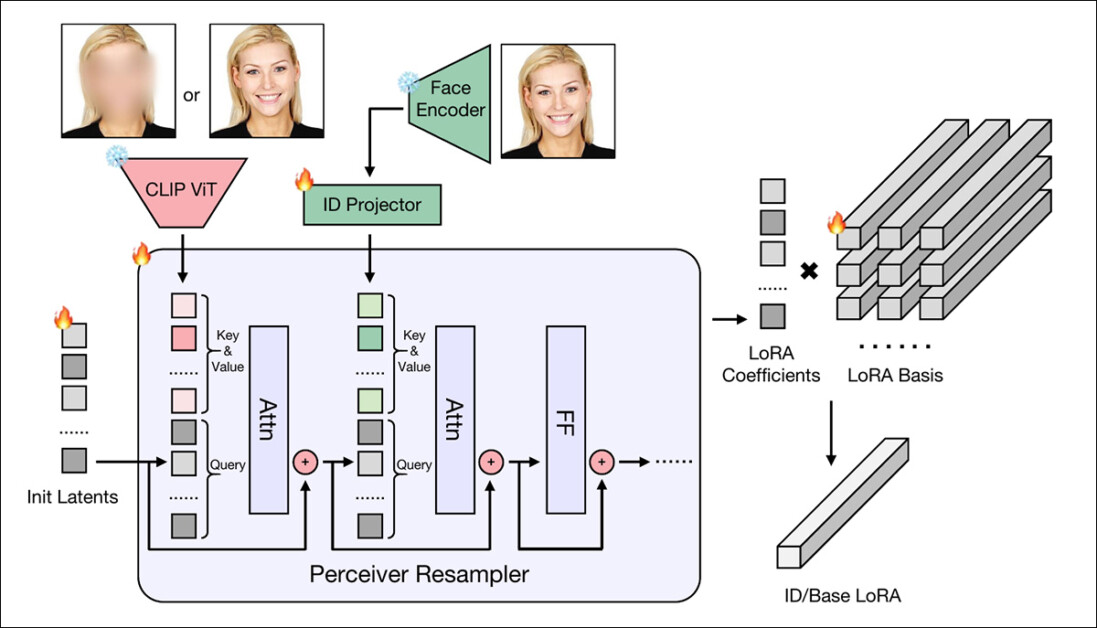
随后,这些输出系数会与一组预训练的LoRA基矩阵进行线性组合,无需微调基础模型就能生成完整的LoRA权重。
这种方法仅需图像编码器和轻量级投影运算,就能实时生成个性化权重,同时充分发挥LoRA直接调控基础模型行为的优势。
数据和测试
为训练HyperLoRA,研究团队从LAION-2B数据集中选取了440万张人脸图像子集(该数据集正是2022年原始Stable Diffusion模型的训练数据来源)。
通过InsightFace筛选剔除非人像及重复图像后,所有图片均使用BLIP-2系统自动标注。在数据增强环节,研究人员采用随机面部区域裁剪策略,始终确保图像聚焦人脸特征。
由于受限于训练硬件内存,各LoRA模块的秩(rank)需动态调整:
身份LoRA(ID-LoRA)秩设为8
基础LoRA(Base-LoRA)秩设为4
同时采用八步梯度累积来模拟更大批次的训练效果
具体训练安排如下:
1基础LoRA模块:20,000次迭代
2身份LoRA(CLIP分支):15,000次迭代
3身份LoRA(特征嵌入分支):55,000次迭代
在身份LoRA训练阶段,系统按0.9/0.05/0.05的概率采样三种条件组合
整个系统基于PyTorch和Diffusers框架实现,在16块NVIDIA A100显卡上耗时约十天完成训练(640GB或1280GB的VRAM,具体取决于使用的型号)。
ComfyUI 测试
研究者在ComfyUI合成平台中构建了工作流程,将HyperLoRA与三种竞争方法进行对比:InstantID、前文提到的IP-Adapter(具体采用IP-Adapter-FaceID-Portrait框架)以及上述引用的PuLID。所有框架测试均使用相同的初始种子、提示词和采样方法以确保一致性。
作者指出,基于Adapter(而非LoRA)的方法通常需要更低的分类器自由引导(CFG)比例尺度,而LoRA方法(包括HyperLoRA)在这方面更具灵活性。因此为了公平比较,研究者在测试中统一使用了开源SDXL微调检查点变体LEOSAM的Hello World模型。定量测试则采用了Unsplash-50图像数据集作为基准。
指标
在保真度基准测试中,研究者采用两种指标衡量面部相似度:一是通过CLIP图像嵌入(CLIP-I)计算余弦距离,二是通过训练阶段未使用的CurricularFace模型提取独立身份嵌入(ID Sim)进行比对。测试时,每种方法为每个身份生成四张高清肖像,最终取平均值作为结果。
编辑能力评估则采用双重标准:一方面比较启用与禁用身份模块时的CLIP-I得分差异,以此衡量身份约束对图像的改变程度;另一方面通过十组涵盖发型、配饰、服装和背景的提示词变体,检测CLIP图文对齐度(CLIP-T)。实验还将Arc2Face基础模型纳入对比,该基线模型采用固定描述文本和裁剪面部区域进行训练。
针对HyperLoRA特别测试了两个变体:仅使用ID-LoRA模块的版本,以及同时使用ID-LoRA与权重设为0.4的Base-LoRA的复合版本。测试发现Base-LoRA虽能提升保真度,但会轻微限制编辑灵活性。
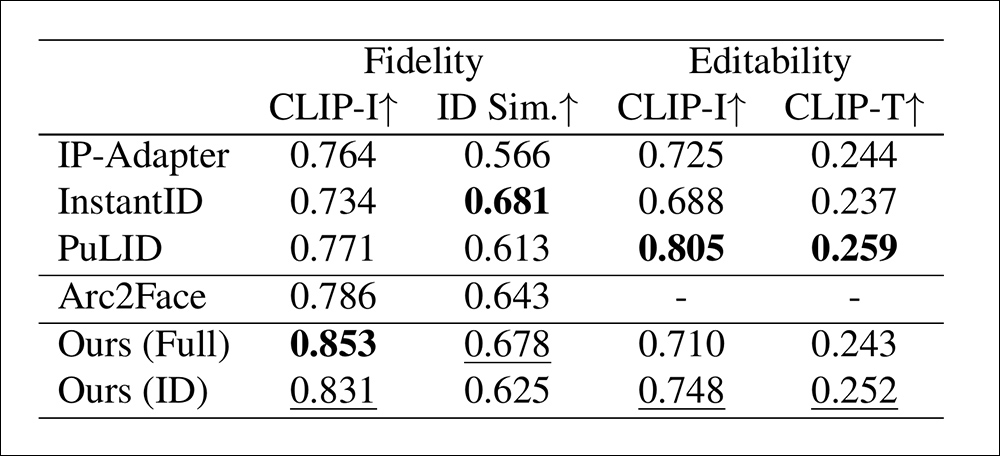
在定量测试结果分析中,研究者指出:
"基础LoRA模块虽能提升图像保真度,但会限制编辑灵活性。尽管我们的设计已将图像特征解耦至不同LoRA模块,仍难以完全避免特征泄漏。因此可通过调节基础LoRA权重来适配不同应用场景。"
"HyperLoRA完整版与纯ID版分别占据面部保真度指标第一、二位,而InstantID在身份相似度上表现优异但保真度较低。评估时需综合考量这两个指标——身份相似度反映抽象特征,而保真度则呈现细节表现。"
定性测试结果(受篇幅限制无法展示全部高清对比图像,详见原文图示)清晰展现了不同方法的核心权衡关系:

研究者特别指出:
"IP-Adapter和InstantID生成的肖像皮肤存在明显AI纹理,存在[色彩过饱和]问题,与真实照片相去甚远。这是基于Adapter方法的通病。PuLID通过减弱对基础模型的侵入性改善了这个问题,虽优于前两者但仍存在模糊和细节缺失。"
"相比之下,LoRA直接修改基础模型权重而非引入额外注意力模块,通常能生成高度细腻的逼真图像。"
作者强调,HyperLoRA直接调整基础模型权重的特性,使其保留了传统LoRA方法的非线性表达能力,在保真度方面具有优势,能更好地捕捉瞳孔颜色等细微特征。定性对比显示,HyperLoRA的画面构图不仅比InstantID和IP-Adapter更符合提示词要求(后两者时常出现构图不自然或偏离提示的情况),其连贯性也与PuLID相当。

结论
过去18个月层出不穷的"单样本定制"系统,已然显露出某种技术焦虑——这些方案大多未能显著推进技术前沿,即便偶有突破,也往往伴随着惊人的训练成本,或面临极其复杂、资源密集的推理需求。
尽管HyperLoRA的训练规模与近期同类研究一样令人咋舌,但至少其最终产出的模型能够实现开箱即用的即时定制。根据论文补充材料,HyperLoRA的推理速度优于IP-Adapter,但逊于另外两种对比方法。需要说明的是,这些测试数据基于NVIDIA V100专业显卡(其32GB显存上限虽已被新款消费级显卡超越,但仍非典型家用设备)。

可以公允地说,从实际应用角度来看,零样本定制仍是一个未解的难题——HyperLoRA虽然表现出色,但其苛刻的硬件需求与构建长期通用基础模型的目标存在着根本性矛盾。
精选文章:
35536块“金砖”砌成的上海新地标,土到窒息还是有钱任性?