
当前的人工智能模型无法识别图像间的“关系”相似性,例如地球的层状结构如何与桃子相似,这缺失了人类感知图像的一个关键方面。
尽管已有许多能够比较图像并发现其间相似性的计算机视觉模型,但当前一代的比较系统几乎不具备想象力。回想20世纪60年代经典歌曲《你心中的风车》中的几句歌词:
像旋转的旋转木马,绕着月亮画圈
像指针扫过表盘分秒的时钟
世界像一颗苹果,在太空中悄然旋转
此类比喻代表了一个富有诗意的隐喻领域,其对人类的意义远超艺术表达本身;相反,它与我们如何发展自身的感知系统紧密相连;在我们构建“对象”领域时,我们发展出视觉相似性认知能力,以至于——例如——描绘桃子和地球的剖面图,或咖啡螺旋与星系分支等分形递归,能够被我们识别为类比关系。
通过这种方式,我们可以推断出看似无关的物体及物体类型之间的联系,并推导出适用于不同领域、不同尺度的系统规律(例如重力、动量和表面凝聚力)。
认知事物
即使是受人类反馈启发的最新图像比较AI系统,如学习感知图像块相似性 (LPIPS) 和 DINO,也只进行字面的表面比较。
它们在不存在面孔的地方发现面孔的能力——即空想性错视——并不代表人类发展出的那种视觉相似性机制,而是因为面部识别算法使用了低层次的面部结构特征,这些特征有时会与随机物体吻合:

'Faces with Things' 数据集中人脸识别的误报示例。来源
为了确定机器是否真的能够发展出我们那种跨领域识别视觉相似性的想象力,美国的研究人员进行了一项围绕关系视觉相似性的研究,策划并训练了一个新的数据集,旨在迫使不同物体之间形成抽象关系,这些物体通过抽象关系相互关联:

大多数AI模型仅在图像共享形状或颜色等表面特征时才识别相似性,因此它们只会将上图中的B组图像与参照图联系起来。相比之下,人类也会认为A组图像相似——并非因为图像看起来相似,而是因为它们遵循相同的底层逻辑,例如展示随时间推移的转变。这项新工作试图复现这种结构或关系相似性,旨在使机器感知更接近人类推理。
为该数据集开发的标注系统促进了异常抽象的注释,旨在迫使AI系统关注基本特征,而非特定的局部细节:

预测的“匿名”标注,这些标注构成了作者提出的“relsim”度量标准。
经过精心策划的数据集及其独特的标注风格,催生了作者新提出的度量标准 relsim,作者已将其微调为一个视觉-语言模型 (VLM)。
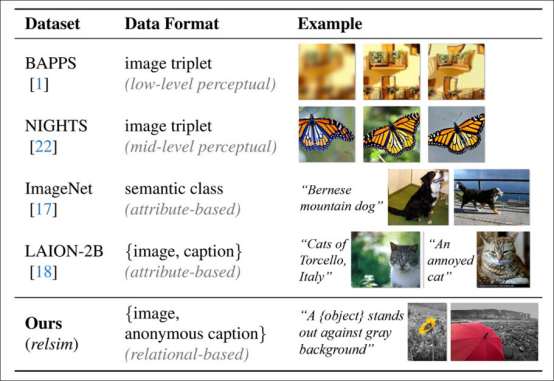
典型数据集的标注风格(关注属性相似性)与 relsim 方法(底行,强调关系相似性)的比较。
这项新方法借鉴了认知科学的方法论,特别是 Dedre Gentner 的结构映射理论(类比研究)和 Amos Tversky 对关系相似性与属性相似性的定义。
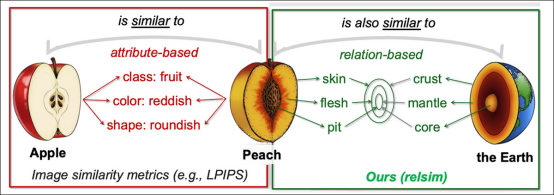
来自相关项目网站的关系相似性示例。来源
作者指出:
‘[人类] 通过感知处理属性相似性,但关系相似性需要概念抽象,通常需要语言或先验知识的支持。这表明,识别关系相似性首先需要理解图像,利用知识,并抽象出其底层结构。’
方法
研究人员以最著名的超大规模数据集之一作为他们自己数据集的起点——LAION-2B:
LAION-2B 数据集中一个条目的元数据。来源
从 LAION-2B 中提取了 114,000 张可能包含弹性关系结构的图像,这涉及过滤掉这个最小化人工筛选数据集中存在的许多低质量图像。
为了为此选择过程创建一个流程,作者利用了 Qwen2.5-VL-7B,并基于 1,300 个正面和 11,000 个负面的人工标注示例:
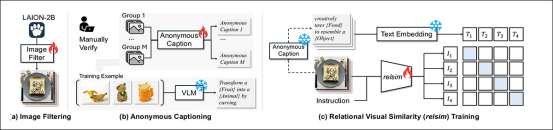
relsim 系统分三个阶段训练:从 LAION-2B 中筛选具有关系内容的图像;为每组图像分配一个共享的匿名标题以捕捉其底层逻辑;以及学习使用对比损失将图像与这些标题进行匹配。
论文指出:
*‘标注员被指示:“你能在这张图片中看到任何可用于创建或链接到另一张图片的关系模式、逻辑或结构吗?”。经过微调的模型与人类判断达到了 93% 的一致性,当应用于 LAION-2B 时,它识别出 N = 114k 张具有关系趣味的图像。’*
为了生成关系标签,研究人员提示 Qwen 模型描述一组图像背后的共享逻辑,而不提及具体物体名称。当模型只看到一张图像时,这种抽象很难获得,但当多个示例展示了底层模式时,这变得可行。
生成的组级标题用占位符如 '{主体}' 或 '{运动类型}' 替换了特定术语,使其具有广泛的适用性。
经过人工验证后,每个标题都与其组中的所有图像配对。使用了超过 500 个这样的组来训练模型,然后将该模型应用于筛选出的 114,000 张图像,以产生一个大型的、带有抽象关系注释的样本集。
数据与测试
使用 Qwen2.5-VL-7B 提取关系特征后,通过八块 A100 GPU 使用 LoRA 在数据上对模型进行了 15,000 步的微调*。在文本方面,关系标题使用来自 Sentence-Transformers 库 的 all-MiniLM-L6-v2 进行嵌入。
114,000 张带标题的图像数据集被分割成 100,000 张用于训练,14,000 张用于评估。为了测试该系统,使用了一种检索设置:给定一个查询图像,模型必须从一个包含 28,000 张图像的池中找到另一张表达相同关系概念的图像。检索池包括 14,000 张评估图像和来自 LAION-2B 的另外 14,000 张样本,从评估集中随机选择 1,000 个查询进行基准测试。
为了评估检索质量,使用 GPT-4o 对每个查询图像与检索到的图像之间的关系相似性进行评分,评分范围为 0 到 10。还进行了一项单独的人工研究以衡量用户偏好(见下文)。
每位参与者会看到一个匿名的查询图像和两个候选图像,一个由提出的方法检索到,另一个由基线方法检索到。参与者被问及哪张图像在关系上与查询更相似,或者两者是否同样接近。对于每个基线方法,创建了 300 组三元组,每组由至少三人评分,产生约 900 份回答。
relsim 方法与几种成熟的图像到图像相似性方法进行了比较,包括前面提到的 LPIPS 和 DINO,以及 dreamsim 和 CLIP-I。除了直接计算图像对之间相似性分数的基线(如 LPIPS、DINO、dreamsim 和 CLIP-I)外,作者还测试了基于标题的方法,即使用 Qwen 为每张图像生成一个匿名或抽象的标题,然后将其作为检索查询。
评估了两种检索变体:使用基于 CLIP 的文本到图像检索 (CLIP-T) 进行文本到图像检索,以及使用 Qwen-T 进行文本到文本检索。两种基于标题的基线都使用了原始的预训练 Qwen 模型,而非在关系逻辑上微调的版本。这使得作者能够隔离基于组训练的效果,因为微调模型接触的是图像组,而非孤立的示例。
现有度量标准与关系相似性
作者首先测试了现有度量标准是否能捕捉关系相似性:
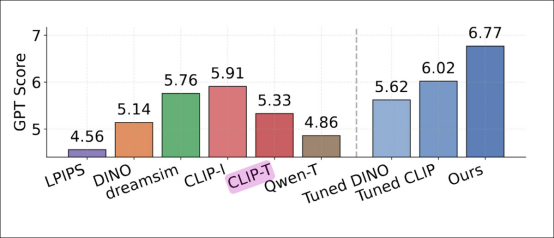
由 GPT-4o 判断的检索性能比较,显示了每种方法的平均关系相似性分数。传统相似性度量标准如 LPIPS、DINO 和 CLIP-I 得分较低。基于标题的基线 Qwen-T 和 CLIP-T 也表现不佳。最高分由 relsim 获得 (6.77,最右侧蓝色柱状图),表明基于组关系模式的微调提高了与 GPT-4o 评估的一致性。
关于这些结果,作者指出**:
*‘[LPIPS] 纯粹关注感知相似性,得分最低 (4.56)。[DINO] 表现略好 (5.14),可能因为其仅通过自监督方式在图像数据上训练。[CLIP-I] 在基线中产生了最强的结果 (5.91),大概是因为图像标题中有时存在一些抽象。*
‘然而,CLIP-I 相对于我们的方法仍然表现不佳,因为要获得更好的分数可能需要达到更高层次的抽象能力,例如匿名标题中的那些抽象。’
在用户研究中,人类在所有基线方法中一致倾向于 relsim 方法:
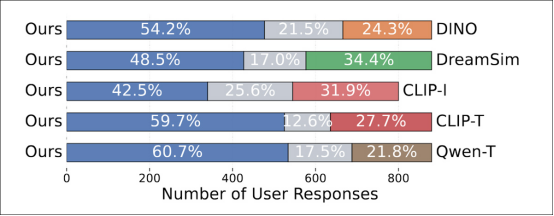
GPT-4o 为每种方法分配的关系相似性分数。标准相似性度量标准如 LPIPS、DINO 和 CLIP-I 得分较低,基于标题的变体 Qwen-T 和 CLIP-T 仅表现稍好。即使是经过调整的 DINO 和 CLIP 版本也无法缩小差距。最高分 6.77 由经过组监督训练的 relsim 模型获得。
作者指出:
‘这非常令人鼓舞,因为它不仅表明我们的模型 relsim 能够成功检索关系相似的图像,并且再次证实了人类确实能感知关系相似性——而不仅仅是属性相似性!’
为了探索关系相似性和属性相似性如何相互补充,研究人员使用了一种组合可视化方法。将一个查询图像('一只拿着相机的狗')与 3,000 张随机图像进行比较,并使用关系和属性模型计算相似性:
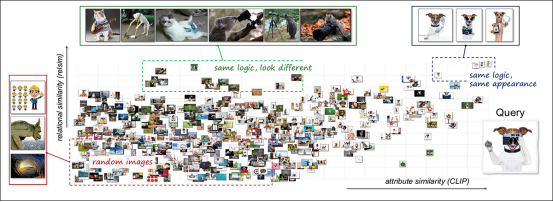
使用关系和属性轴对视觉相似性空间进行联合可视化。将单个查询图像(描绘一只狗使用相机)与另外 3,000 张图像进行比较。结果按关系相似性(垂直)和属性相似性(水平)组织。右上角区域包含在逻辑和外观上都与查询相似的图像,例如其他使用工具的狗。左上角包含语义相关但视觉上不同的情况,例如不同动物执行与相机相关的动作。大多数其余示例聚集在空间下部,反映出较弱的相似性。该布局说明了关系和属性模型如何突出视觉数据的互补方面。请参阅源论文以获得更高分辨率。
结果揭示了对应于不同类型相似性的聚类:有些图像在关系和视觉上都相似,例如其他呈现拟人姿态的狗;另一些共享关系逻辑但外观不同,例如模仿人类动作的不同动物;其余的则两者都不具备。
该分析表明,这两种相似性类型扮演着不同的角色,结合使用时能产生更丰富的结构。
应用场景
论文还探讨了关系相似性的一些潜在最终用途,包括关系图像检索,这使得图像搜索更符合人类自身观察世界的创造性方式:

关系检索返回与查询共享更深层次概念结构的图像,而非匹配表面特征。例如,一个被设计成类似面孔的食物会检索到其他人形化餐点;一个被切片的物体会产生其他切片形式;描绘成年-后代互动的场景会返回具有类似关系角色的图像,即使物种和构图不同。
另一种可能性是类比图像生成,这将允许使用关系结构而非直接描述来合成查询。在对当前一代最先进的文本到图像模型获得的结果进行比较时,我们可以看到这种方法的结果可能会更加多样化:

给定一张输入图像和一个关系提示,要求模型生成一张表达相同底层概念的新图像。专有模型产生了更忠实于原意的类比,在形式发生巨大变化时仍保留了结构逻辑,而开源模型则倾向于回归字面或风格匹配,未能传递更深层次的思想。输出结果与人工策划的类比进行了比较,这些类比展示了预期的转换。
结论
生成式人工智能系统似乎将因其概念化过程中融入抽象表征的能力而显著增强。就目前而言,请求基于概念的图像(如“愤怒”或“快乐”)往往会返回数据集中与这些关联最流行或最多见的图像风格;这是记忆而非抽象。
可以想见,如果这一原则能够应用于生成式写作——特别是分析性、推测性或虚构性输出——可能会带来更大的益处。
精选文章: