
韩国科学技术院(KAIST)人工智能研究所的三位研究人员开发了一种名为"链式变焦"(Chain-of-Zoom)的创新框架。该技术能够利用现有的超分辨率模型生成极致放大的图像,且无需进行模型重新训练。
在这项发表于《arXiv》预印本平台的研究中,Bryan Sangwoo Kim、Jeongsol Kim和Jong Chul Ye三位研究者将图像放大过程分解为多个步骤,并在每个步骤中应用现有超分辨率模型进行渐进式画质提升,最终实现分辨率的多级优化。
研究团队首先指出,当前主流的图像分辨率提升框架多采用插值或回归方法进行放大,这往往会导致图像模糊。为解决这一问题,他们开创性地采用了分步变焦技术——通过前后步骤的迭代优化来实现画质提升。
由于该技术采用了多级处理链来提升分辨率,研究人员将其命名为"链式变焦"(CoZ)框架。
在每一级处理中,该框架都会调用现有的超分辨率(SR)模型启动优化流程。与此同时,视觉语言模型(VLM)会生成描述性提示词,辅助SR模型完成图像生成过程。最终输出的就是原始图像某个局部区域的放大版本。
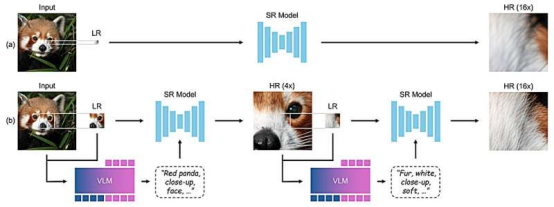
该框架随后会循环这一过程,在视觉语言模型生成的有效提示词辅助下,不断优化放大图像的分辨率,直至生成最终版本。为确保视觉语言模型生成的提示词切实有效,研究团队应用了强化学习技术进行优化。测试结果表明,该框架生成的图像质量超越了标准基准测试的水平。
研究人员特别强调,该框架无需重新训练就能提升图像质量,这使得它具有更好的通用性。但同时他们也提醒使用者必须谨慎对待该技术的应用场景——这些放大后的图像并非真实画面,而是人工智能生成的产物。
举例来说,如果用它来放大银行抢劫案中逃逸车辆的牌照,系统可能会显示出非常清晰的字母和数字,但这些内容可能与真实车牌并不相符。
精选文章:
大作洗眼 | 2025 DIELINE最佳包装、普京“悬空别墅”…全面性设计!